
Don’t forget the immortal science of Marxism-Leninism
AernaLingus [any]
- 0 Posts
- 31 Comments
Joined 4 years ago
Cake day: May 6th, 2022
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.

 37·1 year ago
37·1 year agoFrom 2008 to 2011, Li made CRACK99 a reliable black-market marketplace, one that netted an estimated $100 million in sales. His inventory, investigators later said, was valued at over $1 billion.
Since it’s not clear from this write-up, those eye-popping figures (the ones concocted by the Department of Justice) are derived from the prices that the licenses were being sold for by the original companies, so it’s not $100 million in sales but $100 million in “value” (the idea of calculating a $1 billion valuation for the digital “inventory” is even more ridiculous). If you look on the actual crack99 website, you’ll see that most of the cracked software was being sold for anywhere from twenty bucks to maybe a few hundred dollars—this guy was not making millions from this. The government’s sentencing memorandum has the details; this includes the absurd figure of $3,812,241.57 for a single software license of some CAD software called “Catia VR520”, which Li sold to at least one other customer for the princely sum of $100.
 422·1 year ago
422·1 year agoShoutout to my dumbass relatives for sending their DNA to this company—thanks for nothing!
Thank you for sharing–that was a really neat demonstration, and I enjoyed seeing all the troubleshooting as well. Will definitely be subscribing and checking out more of their videos!
 4·2 years ago
4·2 years agoI feel like there’s not much to fight about. I can understand the latter perspective, but from a practical point of view it just makes sense to consistently assign it to AM/PM rather than creating an unnecessary edge case (lord knows there are enough of those with date/time systems). Also this is all made moot by the superior system: the 24-hour clock (now THERE’S something I bet you could have a good argument about!).
I can’t remember the specifics (both because it was dumb and because it’s so embarrassing I think my brain is trying to protect me), but from what I recall I got into a heated argument on the internet with someone because I felt that fans weren’t cheering hard enough for a band I liked at a concert.
…yeah, I know. I’m grateful, though, because it was so colossally stupid and pointless that I had a come-to-Jesus moment and swore off internet arguments entirely. I can only imagine the countless hours of my life it’s saved me in the intervening years.
out-of-order
MyAnonamouse
Boston Chicken & KFC Rotisserie Style Chicken.txt
lmao
Davis states that the original source of the tale was Olayuk Narqitarvik. It was allegedly Olayuk’s grandfather in the 1950s who refused to go to the settlements and thus fashioned a knife from his own feces to facilitate his escape by skinning and disarticulating a dog. Davis has admitted that the story could be “apocryphal”, and that initially he thought the Inuit who told him this story was “pulling his leg”.
That’s a long payoff for a practical joke, but totally worth it.
Also, unsurprisingly, they won the 2020 Ig Nobel Prize in Materials Science (lol) for this one (video of the ceremony, Ig Nobel “lecture” from the lead author (also the primary pooper))
Written a bit more explicitly (although I kinda handwaved away the final term–the point is that you end up with one unpaired term which goes to zero)
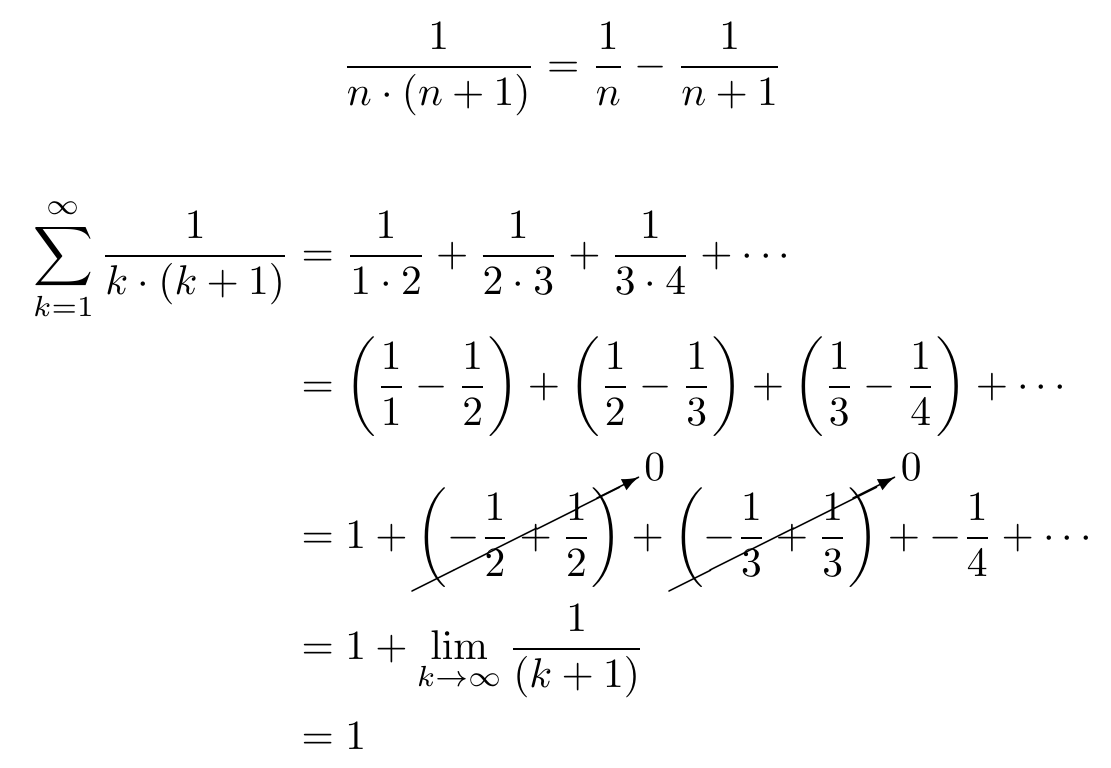
edit: I was honestly confused about how exactly this related to the question, but seeing the comment from @yetAnotherUser@discuss.tchncs.de (not visible from Hexbear) which showed that the first sum in the image is equivalent to
the sum from n = 1 to ∞ of 2/(n * (n + 1))
made things clear (just take the above, put 2 in the numerator, and you get a result of 2)
Facebook (when that was still a platform young people used). I would obsessively scroll through it for hours each day, basically trying to look at and comment on EVERYTHING. On a whim, I decided to take a break from it for a month. By the time the month was up, I realized I didn’t miss it at all, and that was that. One of the big takeaways was that I thought that I was forming relationships with the people I’d comment back and forth with, but in reality these were people who I would never hang out with outside of school and barely even talk with in school (if at all); it was all just superficial, and I was better off spending time talking to my actual friends.
It wasn’t that bad, but in high school I mindlessly got into the habit of drinking a few cups of Coke each day (I think it started because I would get a 2 liter whenever I’d order pizza). I quit it pretty much cold turkey, and not only did I stop drinking it at home, I no longer order it at restaurants either, which is something I did ever since I was a little kid. The idea of just buying a bottle of soda and drinking it is straight honestly grosses me out now even though getting a can or bottle from a vending machine was something I’d do without thinking. The one exception is when I’m pigging out at the movies with a bucket of popcorn, but that’s pretty rare.
Whoa, that looks pretty sick. Definitely will give it a shot next time the need arises!
Here’s an insta of an actual Japanese wildlife photographer chock-full of great photos of this bird (among others)
If you’re watching consecutive episodes of a series you can always just download them to your phone before you head to work. Not really viable if you hop around a lot, though.
Seconded, that beast (well, one of its predecessors) got me through college on the included toner cartridge alone and it’s still kicking
Thanks liberal justices, very cool!
https://www.theguardian.com/science/1999/aug/24/spaceexploration