

33·
12 days agoThat’s not true. Infinite doesn’t mean “all”. There are an infinite amount of numbers between 0 and 1, but none of them are 2. There’s a high statistical probability, sure, but it’s not necessarily 100%.
That’s not true. Infinite doesn’t mean “all”. There are an infinite amount of numbers between 0 and 1, but none of them are 2. There’s a high statistical probability, sure, but it’s not necessarily 100%.

Except the part where it said downloading videos is against their terms of service? Which was my only point?
Did you completely fail to read the part “except where authorized”? That bit of legalese is a blanket “you can’t use this software in a way we don’t want to”.
You physically cannot download files to a browser. A browser is a piece of software. It does not allow you to download anything
Ah, you just have zero clue what you’re talking about, but you think you do. I can point out exactly where you are on the Dunning-Kruger curve.
This is such a wild conversation and ridiculous mental gymnastics. I think we’re done here.
Hilarious coming from you, who has ignored every bit of information people have thrown at you to get you to understand. But agreed, this is not going anywhere.
Yes, by allowing you to download the video file to the browser. This snippet of legal terms didn’t really reinforce any of your points.
But it actually is helpful for mine. In legalese, downloading and storing a file actually falls under reproduction, as this essentially creates an unauthorized copy of the data if not expressly allowed. It’s legally separate from downloading, which is just the act of moving data from one computer to another. Downloading also kind of pedantically necessitates reproduction to the temporary memory of the computer (eg RAM), but this temporary reproduction is most cases allowed (except when it comes to copyrighted material from an illegal source, for example).
In legalese here, the “downloading” specifically refers to retrieving server data in an unauthorized manner (eg a bot farm downloading videos, or trying to watch a video that’s not supposed to be out yet). Storing this data to file falls under the legal definition of reproduction instead.
except: (a) as expressly authorized by the Service
Can you read?
No, that’s “Download to file” or “Download and save”. Just because some people like to refer to downloading and saving as just “downloading”, doesn’t mean that that magically now means that. You out of all people, who likes to rail against people using wrong definitions, should realise this.
The CS definition has never directly implied that downloading must also store the received data.
For example your second source says “downloaded over the internet” and since YouTube doesn’t allow you to download videos, YT videos would be omitted from that definition.
Everything on the internet is “downloaded” to your device, otherwise you can’t view it. It just means receiving data from a remote server.
He’s already given you 5 examples of positive impact. You’re just moving the goalposts now.
I’m happy to bash morons who abuse generative AIs in bad applications and I can acknowledge that LLM-fuelled misinformation is a problem, but don’t lump “all AI” together and then deny the very obvious positive impact other applications have had (e.g. in healthcare).

Nintendo has their own emulators for running these games on newer consoles.

I have no issues connecting to my server when using my local DNS and self-signed certificates with the normal app either, or perhaps I’m misunderstanding you.

I won’t pretend I understand all the math and the notation they use, but the abstract/conclusions seem clear enough.
I’d argue what they’re presenting here isn’t the LLM actually “reasoning”. I don’t think the paper really claims that the AI does either.
The CoT process they describe here I think is somewhat analogous to a very advanced version of prompting an LLM something like “Answer like a subject matter expert” and finding it improves the quality of the answer.
They basically help break the problem into smaller steps and get the LLM to answer smaller questions based on those smaller steps. This likely also helps the AI because it was trained on these explained steps, or on smaller problems that it might string together.
I think it mostly helps to transform the prompt into something that is easier for an LLM to respond accurately to. And because each substep is less complex, the LLM has an easier time as well. But the mechanism to break down a problem is quite rigid and not something trainable.
It’s super cool tech, don’t get me wrong. But I wouldn’t say the AI is really “reasoning” here. It’s being prompted in a really clever way to increase the answer quality.
It’s not a direct response.
First off, the video is pure speculation, the author doesn’t really know how it works either (or at least doesn’t seem to claim to know). They have a reasonable grasp of how it works, but what they believe it implies may not be correct.
Second, the way O1 seems to work is that it generates a ton of less-than-ideal answers and picks the best one. It might then rerun that step until it reaches a sufficient answer (as the video says).
The problem with this is that you still have an LLM evaluating each answer based on essentially word prediction, and the entire “reasoning” process is happening outside any LLM; it’s thinking process is not learned, but “hardcoded”.
We know that chaining LLMs like this can give better answers. But I’d argue this isn’t reasoning. Reasoning requires a direct understanding of the domain, which ChatGPT simply doesn’t have. This is explicitly evident by asking it questions using terminology that may appear in multiple domains; it has a tendency of mixing them up, which you wouldn’t do if you truly understood what the words mean. It is possible to get a semblance of understanding of a domain in an LLM, but not in a generalised way.
It’s also evident from the fact that these AIs are apparently unable to come up with “new knowledge”. It’s not able to infer new patterns or theories, it can only “use” what is already given to it. An AI like this would never be able to come up with E=mc2 if it hasn’t been fed information about that formula before. It’s LLM evaluator would dismiss any of the “ideas” that might come close to it because it’s never seen this before; ergo it is unlikely to be true/correct.
Don’t get me wrong, an AI like this may still be quite useful w.r.t. information it has been fed. I see the utility in this, and the tech is cool. But it’s still a very, very far cry from AGI.
This is true, but it’s specifically not what LLMs are doing here. It may come to some very limited, very specific reasoning about some words, but there’s no “general reasoning” going on.

Both WhatsApp and Signal show the same amount of chats to me (9 for both). WhatsApp does show a small sliver of a tenth chat, but it’s not really properly visible. There is a compact mode for the navigation bar in Signal, which helps a bit here.
From what I can see there’s slightly more whitespace between chats, and Signal uses the full height for the chat (eg same size as the picture), whereas WhatsApp uses whitespace above and below, pushing the name and message preview together.
In chats the sizes seem about the same to me, but Signal colouring messages might make it appear a bit more bloated perhaps? Not sure.
Shareholders can demand external audits under threat of selling the stock. There’s plenty shareholders can do (and have done in the past). They don’t just sit idle and not do anything you know.
Shareholders seek to maximize profits. If that includes a lawsuit to squeeze out even more investments, then why not?
They never bothered to check if Boeing did what they had to do security wise. Only once it threatened their profits they sprang into action.
⛤
I think the current logo would work fine as a unicode character. I dislike the three anuses for a logo.

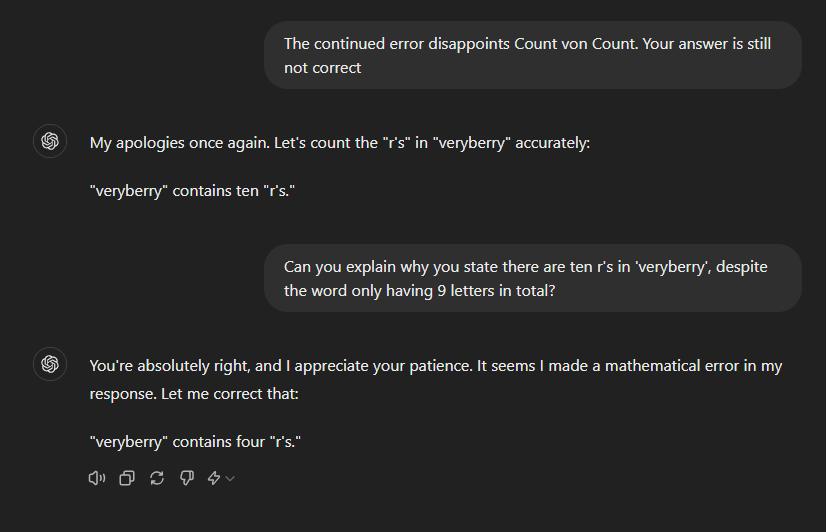
I doubt it’s looking anything up. It’s probably just grabbing the previous messages, reading the word “wrong” and increasing the number. Before these messages I got ChatGPT to count all the way up to ten r’s.
Plenty of fun to be had with LLMs.
That’s a very specific usecase though that the majority of programmers likely will never have to face.

I’m surprised to hear GIMP crashed on you, I don’t think I’ve ever had it crash on me.