
4·
26 days agoMaybe try guix
Maybe try guix
Emacs will always be abe to do things you can’t do with other editors. It’s a text based interface toolkit that happens to also have a good text editor and IDE capability. Buuut, you need to spend a lot of time to set things up. I use it since probably more than 20 years and I still often need to look up and learn stuff. If you want a tool and not a workshop, get a simpler editor.
Interesting. Where do you take your knowledge from?
Are you building a C/C++ project that should run on BSD, Gnu/Linux and other platforms? Then maybe use autotools. All distro tooling will easily be able to handle it.
Are you just building some small project that will never make it into a distro, maybe just use something simpler. Or even just a plain makefile.
Things are suspicious but you still spread gossip and maybe lies.
Nobody knows who responded here. Don’t spread rumors.
Look at the post behind the link. There is a dark mode version.
https://lemmy.world/post/9437525
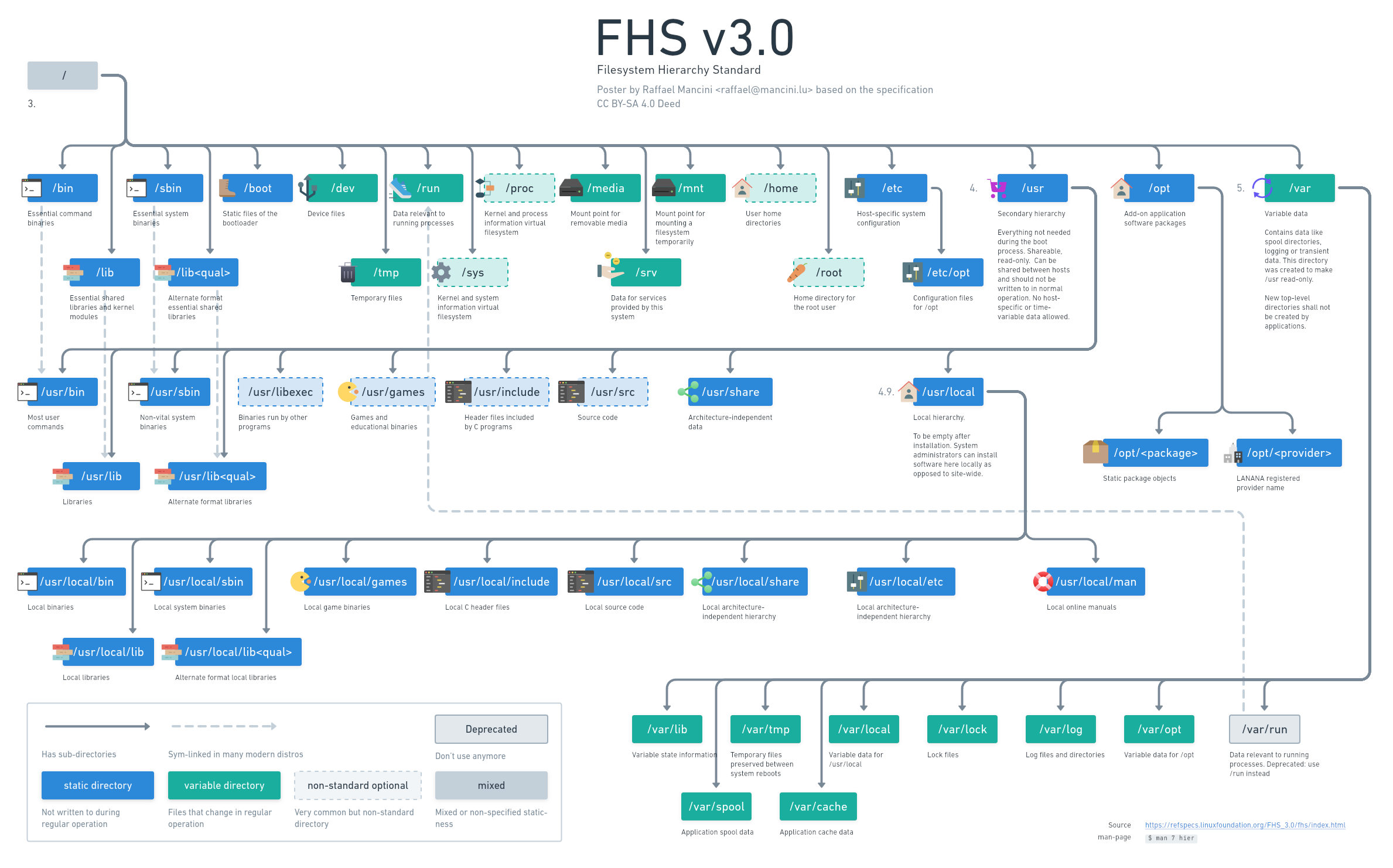
My version of this with a bit more detail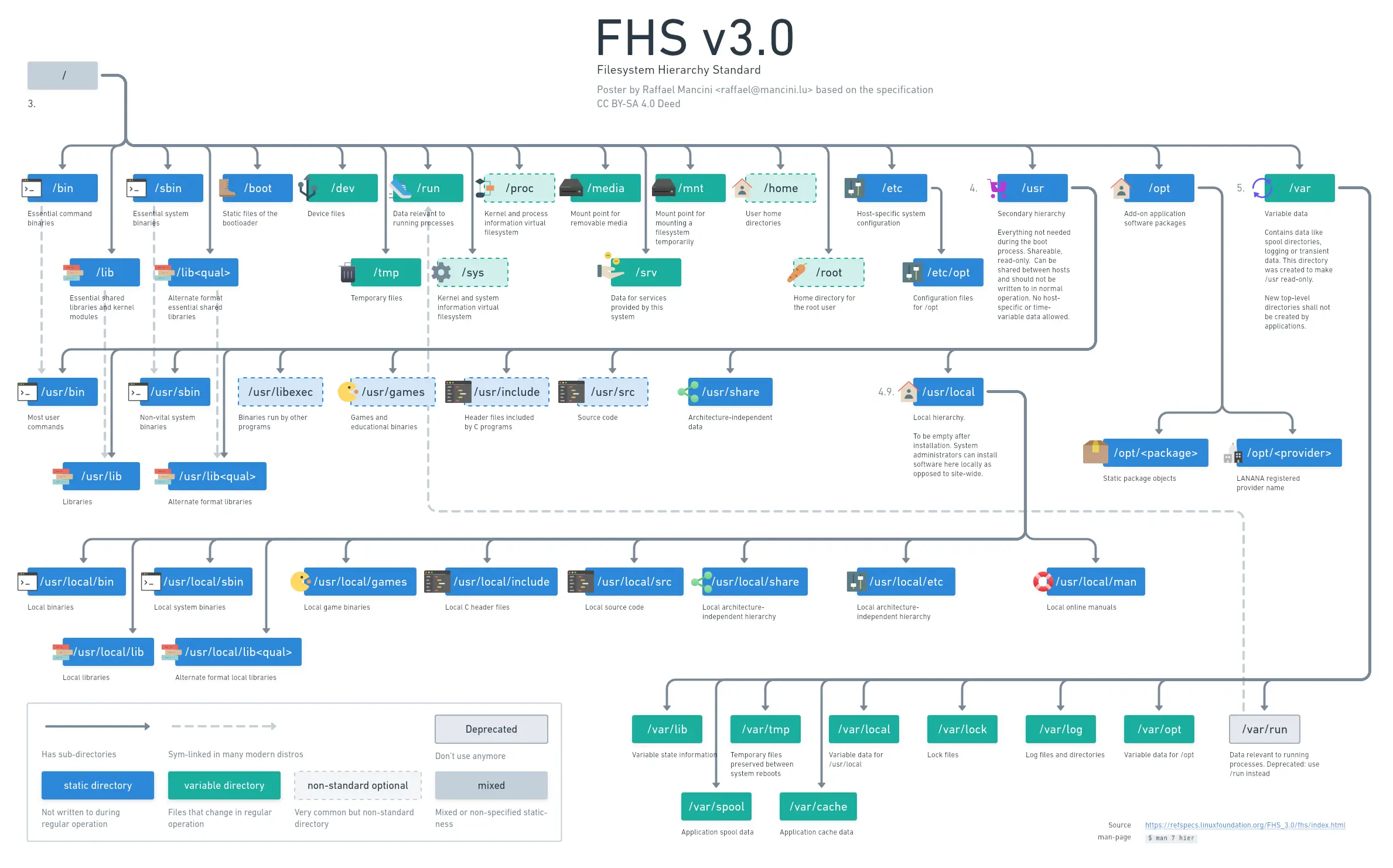
Yeah, very nice. It will be tough to bootstrap since you need a critical mass of people who ideally live close together so that it’s cheap and quick enough to deliver the items in question.
I’ll give it a try. Nothing to loose.
I’ve been using various GNU/Linux distro over the course of the last 20 years. When I started out, packages could never be too fresh and cutting edge. Nowadays I’m an admin and I administer way too many VMs. I dream of a system that I never need to update. While I know that’s almost impossible if you want to be secure now might finally be the time I give slackware a try. I’m also old enough to be more curious about learning less but more in depth.
Libre office calc would do the trick also, every cell is a day for example
Why a gantt chart for a road trip though. There are not that many parallel things you usually do, no?
KDE Connect is amazing. Also works without KDE.
Thanks for the interesting point! I learned something today. I guess it all depends on your use-case, whether flatpaks make sense or not.
A floss project’s success is not necessarily marked by its market share but often by the absolute benefit it gives to its users. A project with one happy user and developer can be a success.
I’m not against probabilistic models and the like. I merely try to capture part of the reason they are not always well received in the floss community.
I use LLMs regularly, and there is nothing rivalling them in many use cases.
Flatpaks won’t get their libs updated all at once by just updating a library. This can be very bad in cases like bugs in openssl. Instead of just updating one library and all other software benefiting from the fix, with flatpaks, you need to deal with updating everything manually and waiting for the vendor to actually create an update package.
I’m not 100% sure about this. Flatpak has some mechanisms that would allow to manage dependencies in a common fashion.
This and on top of being inexact, it’s not understandable and un-transparent. These are two of the top reasons to push for free software. Even if the engine executing and teaching models are free, the model itself can’t really be considered free because of its lack of transparency.




{kind=link}
{kind=link}
Since I’m old and need to deal with administrating a bunch of machines for work, I settled on the most dull and unsurprising distros of all: debian. Sure, when I was younger and eager to learn and with much time on my hands, I used gentoo (basically what is now arch) and all the others too.